











L’accélération de calcul haute performance vient aux plates-formes PXIe/CPCIe

RADX Technologies a dévoilé les premiers modules GPU PXI Express/CompactPCI Express (PXIe/CPCIe) économiques sur étagère du marché.
A l’occasion de l’édition 2022 du salon IEEE Autotestcon, qui s’est tenue du 29 août au 1er août dernier à National Harbor, dans le Maryland (États-Unis), l’Américain RADX Technologies a dévoilé la famille de modules GPU PXI Express/CompactPCI Express (PXIe/CPCIe) économiques Catalyst-GPU.
 Les modules PXIe-GPU-T600-4GB-1SP et PXIe-GPU-T1000-8GB-1SP sont les premiers produits sur étagère, qui apportent l’accélération de calcul haute performance économique et facile à programmer, ainsi que les capacités graphiques avancées des GPU Nvidia Quadro T600 et T1000 aux plates-formes PXIe/CPCIe déployées en test et mesure et dans la guerre électronique.
Les modules PXIe-GPU-T600-4GB-1SP et PXIe-GPU-T1000-8GB-1SP sont les premiers produits sur étagère, qui apportent l’accélération de calcul haute performance économique et facile à programmer, ainsi que les capacités graphiques avancées des GPU Nvidia Quadro T600 et T1000 aux plates-formes PXIe/CPCIe déployées en test et mesure et dans la guerre électronique.
Les Catalyst-GPU sont parfaitement adaptés aux applications d’apprentissage automatique et d’apprentissage profond, qui deviennent de plus en plus importantes pour la classification et la géolocalisation des signaux basés sur l’intelligence artificielle (IA), les tests de semi-conducteurs et de circuits imprimés, la prédiction des pannes, l’analyse des pannes, etc.
Jusqu’à présent, une accélération de calcul de 2,5 TFLOP de puissance FP32 (Catalyst-GPU T1000) – l’accélération est de 1,7 TFLOPS de puissance FP32 pour le Catalyst-GPU T600 – n’était pas disponible dans les systèmes PXIe/CPCIe. Avec les nouveaux modules, les utilisateurs peuvent désormais effectuer une analyse rapide et précise des données acquises directement dans les systèmes PXIe/CPCIe.
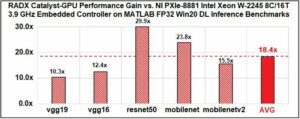
Sur les benchmarks d’inférence Matlab d’apprentissage profond de traitement FP32, le module Catalyst-GPU T1000 apporte un gain de performances moyen d’un facteur de 18,4x par rapport à un contrôleur embarqués PXIe-8881 Xeon W-2245 de NI.
Prenons l’exemple d’un châssis PXIe-1092 associé à un contrôleur embarqué PXIe-8881, doté d’un processeur Intel Xeon W-2245 8C/16T 3,9 GHz, exécutant Windows 10 et Matlab, les deux de NI, le Catalyst-GPU T1000 apporte un gain de performances moyen d’un facteur de 7,1x pour le contrôleur sur des FFT de puissance FP32 allant de 1 000 à 32 millions d’échantillons de longueur. Sous Python, le Catalyst GPU T1000 fournit un gain moyen d’un facteur de 19,2x.
Sur les applications d’apprentissage machine et profond, les gains de performances sont également substantiels. Sur les benchmarks d’inférence d’apprentissage profond de puissance FP32 Matlab, le Catalyst-GPU T1000 assure un gain de performances moyen d’un facteur de 18,4x par rapport à un contrôleur embarqué PXIe doté d’un processeur Intel Xeon W-2245 8C/16T 3,9 GHz (voir ci-contre).
Pour les applications de traitement du signal, les Catalyst-GPU prennent en charge les algorithmes de FFT de longueur arbitraire, de PSD, de corrélation, etc., ce qui permet des précisions et des bandes passantes de résolution qui ne sont pas réalisables dans les systèmes non basés sur GPU.
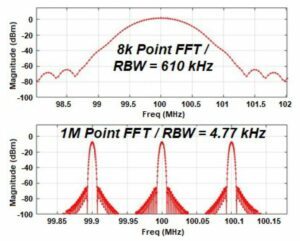
Catalyst-GPU prend en charge les fonctions de DSP de longueur arbitraire pour améliorer la largeur de bande de résolution et la précision pour la détection, l’analyse et la classification des signaux à faible probabilité d’interception.
Si, dans la plupart des FPGA, les longueurs pratiques les plus longues pour les FFT sont généralement de 8 000 points, elles peuvent atteindre 1 Mpoints, voire plus, dans les Catalyst-GPU, et être exécutées en temps réel, ou quasi réel, selon l’application. Des FFT plus longues permettent de révéler bien plus facilement la véritable composition spectrale d’un signal et les signaux à faible probabilité d’interception.
Avec une prise en charge complète de Matlab, Python et C/C++, combinée à la prise en charge de pratiquement tous les frameworks informatiques courants, les GPU Catalyst sont faciles à programmer pour les environnements d’exploitation Windows et Linux.
« La prise en charge intrinsèque de Matlab pour l’accélération GPU Nvidia signifie que les utilisateurs peuvent désormais accélérer leurs applications de traitement du signal et d’IA directement dans leurs systèmes d’acquisition de données PXIe/CPCIe, sans avoir à transporter des gigaoctets ou des téraoctets de données sensibles vers d’autres systèmes d’analyse via Ethernet ou Sneakernet, ni avoir à passer des mois à porter leurs applications sur d’autres plates-formes », explique Ross Q. Smith, cofondateur et CEO de RADX Technologies.








